Entity Extraction
Entity Extraction, also known as Named Entity Recognition, is the process of identifying information of interest, such as people and places.
Text is structured into a Text Graph, Tokens and Nodes so it can be analysed and Annotations marked up. Entities and Text References and links are marked up within a Document using annotations on the Text Graph.
Natural Language Processing
Entity Extraction is a branch of Natural Language Processing, also known as Large Language Models. Natural language processing allows computers to understand and interpret language as well as generate text and speech.
Artificial Intelligence
Natural Language Processing is one technology used to create Artificial Intelligence.
Artificial intelligence is a collection of technologies that aim to perform tasks that typically require human intelligence, including Machine Learning, Natural Language Processing, Computer Vision, Deep Learning, Robotics and Speech Recognition.
Challenges in Entity Extraction
Named Entity Resolution can face challenges. While London can be easily identified as the capital city of England, there are actually 29 places in the world called London!
London can also be a person's given name or family name! Therefore, the context of where and how a word is used can change its meaning.
Think about how many ways we can refer to a person. For example, John London may also be referred to as J London, Mr. London, John, London, he, his, etc. Now imagine trying to figure out who is who when so many varied references are used across thousands of documents
Entity Extraction Models
There are different Entity Extraction models available. These models can vary in the speed and accuracy with which they perform Entity Extraction. Further, different models may be capable of performing Entity Extraction for a different range of languages.
Entity Extraction Mode
Sintelix provides two Entity Extraction modes:
-
Baseline: The Baseline Entity Extraction model is built into Sintelix. It can run on a standard computer using CPU processing.
-
Enhanced: The enhanced Entity Extraction model boasts improved accuracy, but is slower than the Baseline Entity Extraction mode. It needs to be installed separately and requires a computer to have access to compatible GPUs.
Configuration
The Entity Extraction mode used during Ingestion is configured in the Document Processing configuration. (See Enhanced Extraction).
Language Pipelines
Every language has its own vocabulary and grammatical rules. Therefore, each language requires its own Entity Extraction method, called a pipeline. See Languages.
Language pipelines need to be licensed.
Select the Status tab to view the language pipelines supported, installed and licensed. (Enhanced) displayed after the language name indicates the Entity Extraction enhanced mode is installed (see below). For example,  .
.
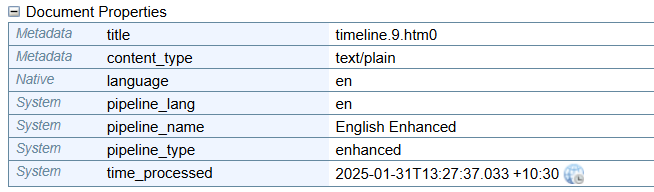
The pipeline applied to a Document is displayed in the Document Properties section as the pipeline_type:

If Enhanced Entity Extraction has been applied, the pipeline_type will be show the value enhanced.
Links
By examining the context of the words, you can identify Connections between Entities.
For example:
-
an Organisation is based in a Location
-
a Person works for an Organisation
-
a Person is the uncle of another Person, etc.
These Connections are captured in Documents and become Links in Networks.
Clustering
Clustering is a way of grouping similar information. Imagine analysing thousands of news reports and finding hundreds of references to "John London" who may or may not be the same person. How do you tell them apart?
Clustering looks for patterns, similarities and differentiators to distinguish between references and the connections between them.
For example:
-
John London from Sydney, works for Caltex and is not married.
-
John London from Washington, works for Microsoft and is married to Mary.
-
John London from Manchester is married to Maria but it's not clear where he works as an accountant.
Clustering the entities and links found in Documents results in a Network.
Network
A Network is a collection of Nodes and Links.
-
Nodes include Entities and Documents.
-
Links are connections between nodes, for example, from Entity to Entity or Entity to Document.
A Network allows users to analyse and visualise information extracted from a vast volume of data contained in Documents.